Vigorish: Hybrid Python/Node.Js Web Scraper

Photo by Patti Black on Unsplash
Table of Contents
Usage
Congratulations! If you made it this far, you have successfully installed and configured vigorish! After installing Nightmare/Electron and initializing the database, the Main Menu will display three new options (Create New Job, View All Jobs and Status Reports):
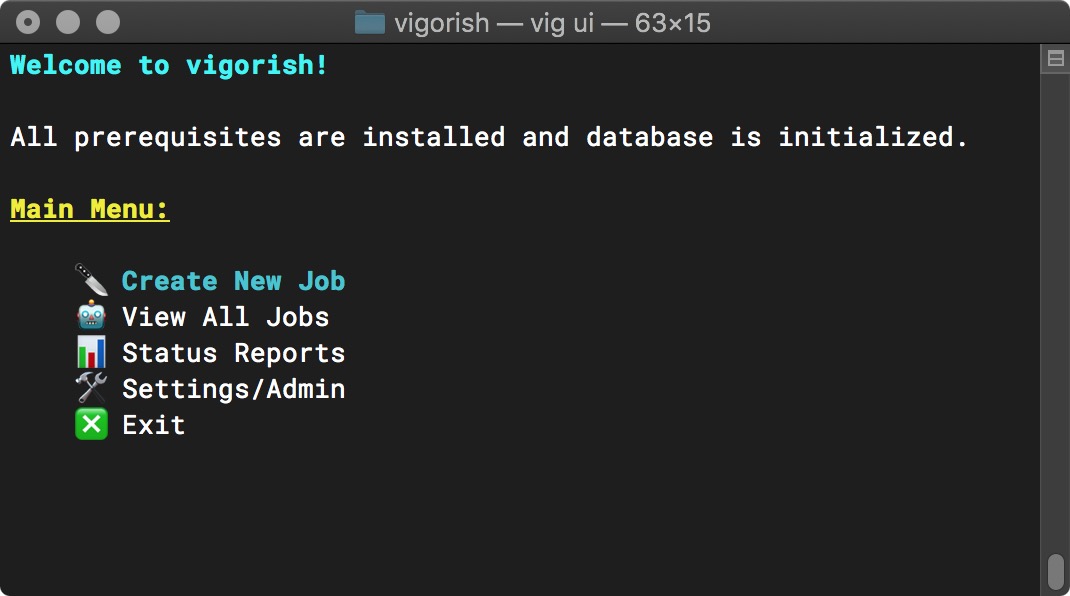
Main Menu (Setup Complete)
Warning!
Use of vigorish must abide by the terms stated in the license. Also, in order to abide by the guidelines quoted below (from baseball-reference.com), a delay of at least two seconds MUST always occur after a URL is scraped:
Please do not attempt to aggressively spider data from our web sites, as spidering violates the terms and conditions that govern your use of our web sites: Site Terms of Use … If we notice excessive activity from a particular IP address we will be forced to take appropriate measures, which will include, but not be limited to, blocking that IP address. We thank you in advance for respecting our terms of use.
Create New Job
After selecting Create New Job from the Main Menu, you are prompted to select the data sets you wish to scrape. Currently, vigorish allows you to collect five data sets from two different web sites:
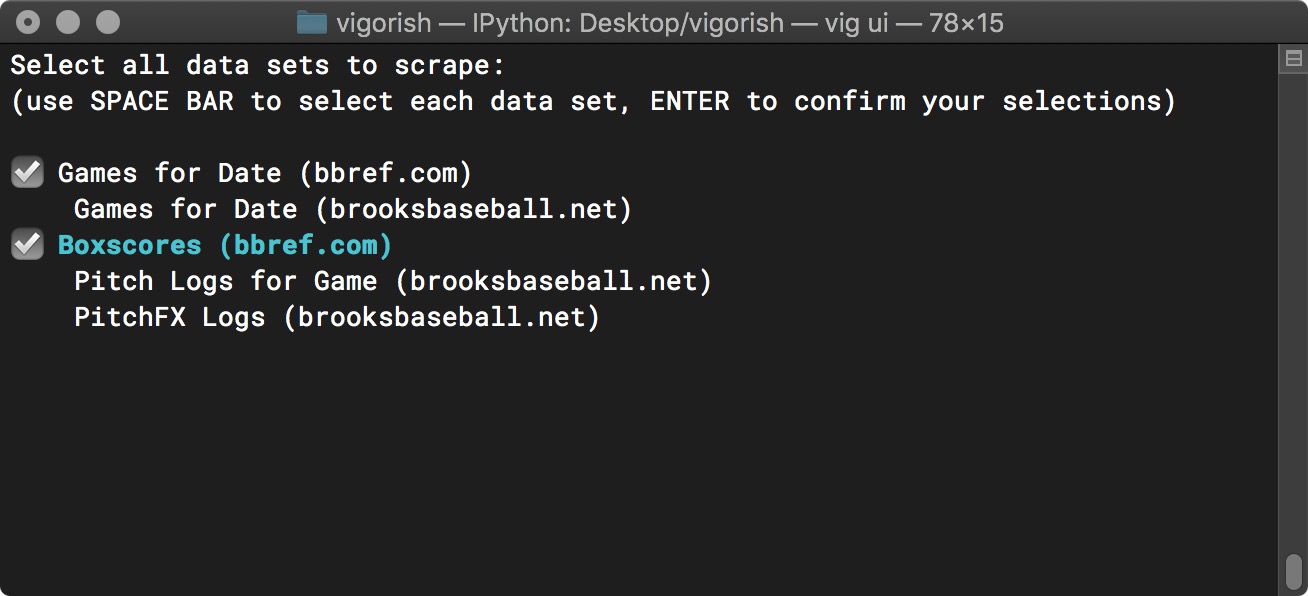
Create Job Step 1a - Select Data Sets
Since this prompt allows you to select multiple items, it behaves differently than other prompts. To select a data set, highlight it and press Space. A checkmark will appear next to the data set indicating that it has been selected (you can deselect a selected item by pressing Space as well). When you are satisfied with your selections, press Enter to move on to the next step.
Next, you will be prompted to enter the start and end dates you wish to scrape and a name for this job:
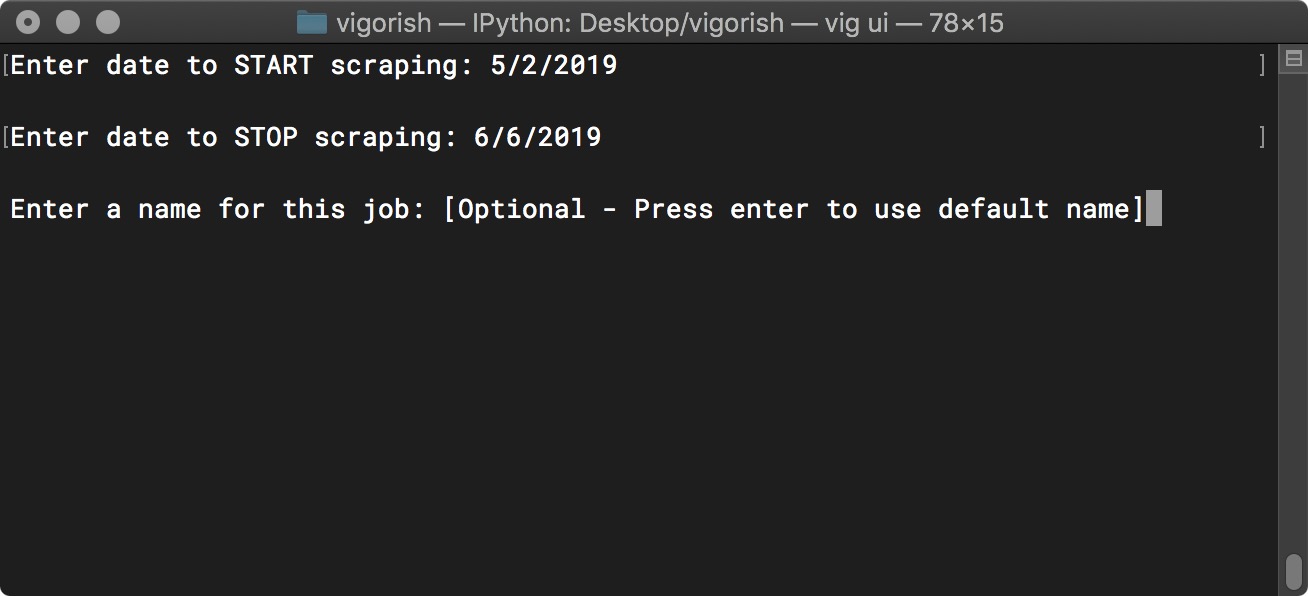
Create Job Step 2a - Edit Job Details
If the values you provided for the start/end dates are valid, you will be prompted to enter a name for this job. As mentioned in the prompt, this value is optional. You can bypass this prompt simply by pressing Enter.
Even if you have entered two valid dates for the start/end dates, you may receive an error message and be prompted to re-enter both dates. For example, both dates must have the same year and must be within the MLB regular season for that year. If you enter a date before or after the regular season, the error message will tell you the valid date range:
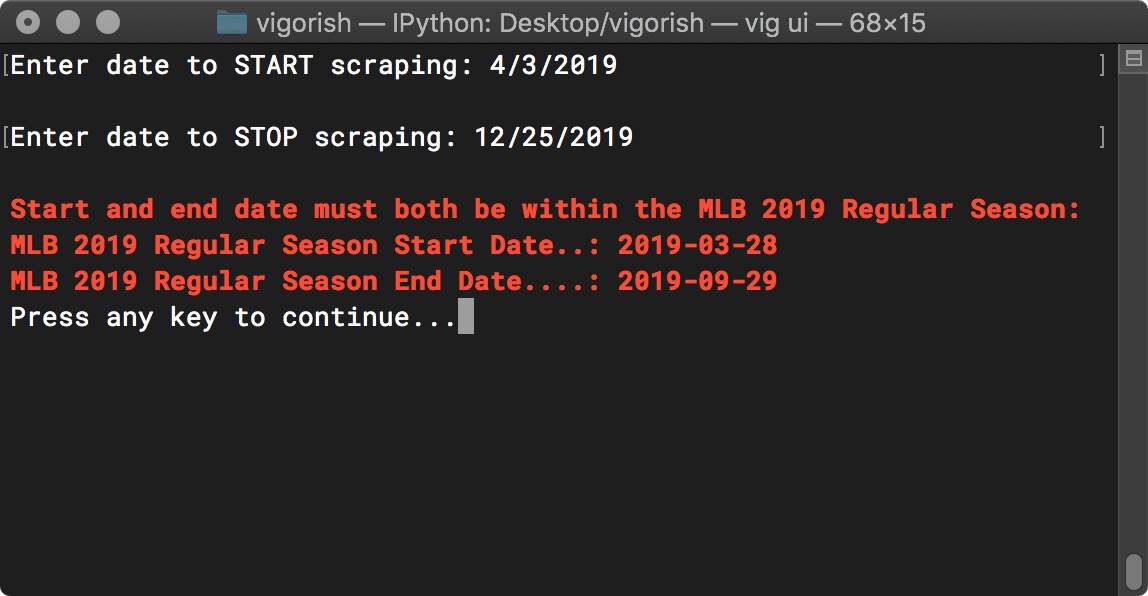
Start/End Date Error - Date Is Not Within Regular Season
Another error occurs when you enter a end date that is before the start date. Obviously, the end date needs to be a date after (or the same date as) the start date. If that occurs, you will see an error similar to this:
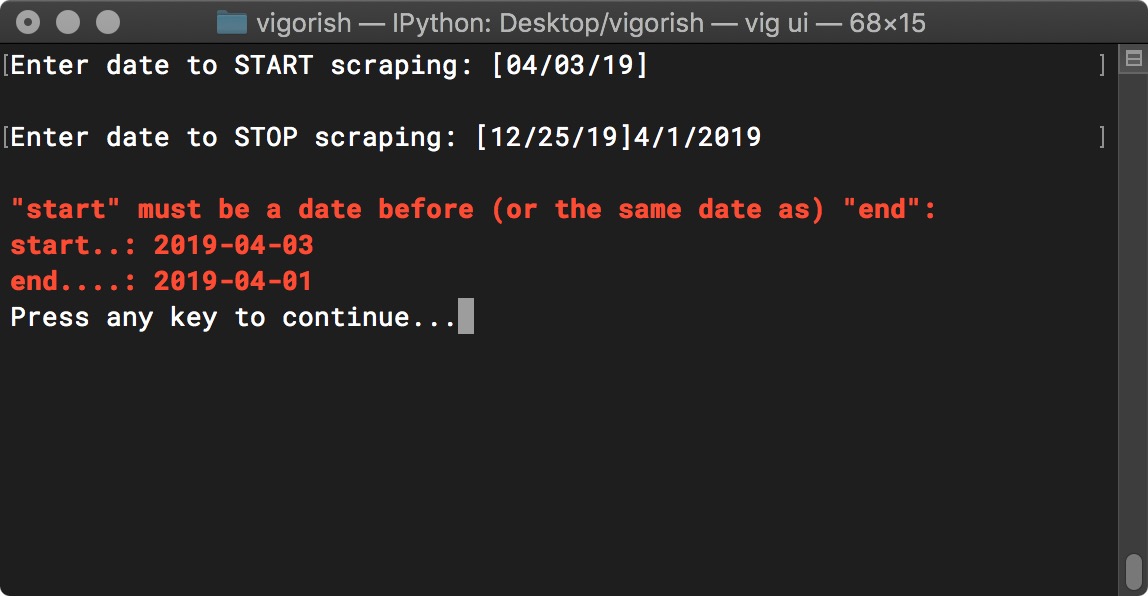
Start/End Date Error - End Date Occurs Before Start Date
The next screen will display a summary of the job details, and asks you to confirm that they are correct:
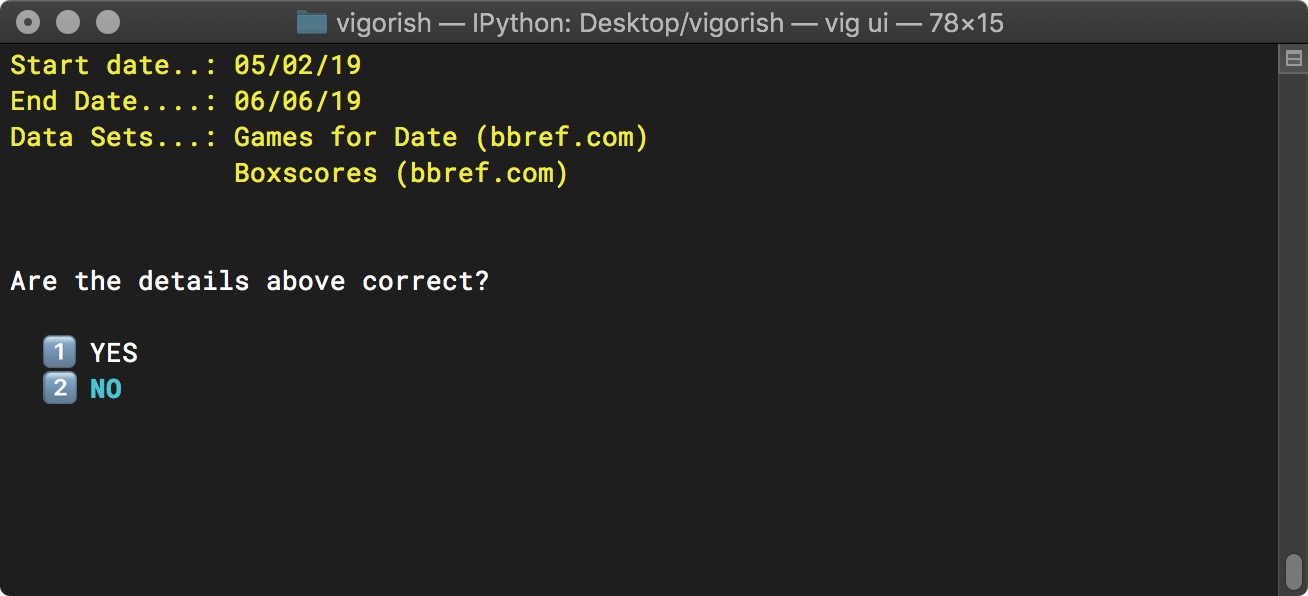
Create Job Step 3a - Confirm Job Details
If you need to change anything, select NO as shown in the screen above and press Enter. You will be returned to the menu to select the data sets to scrape. Helpfully, the data sets that you selected are already checked. If you do not need to change the selected data sets, simply press Enter to move on to the next menu.
In the example below, all data sets are now selected:
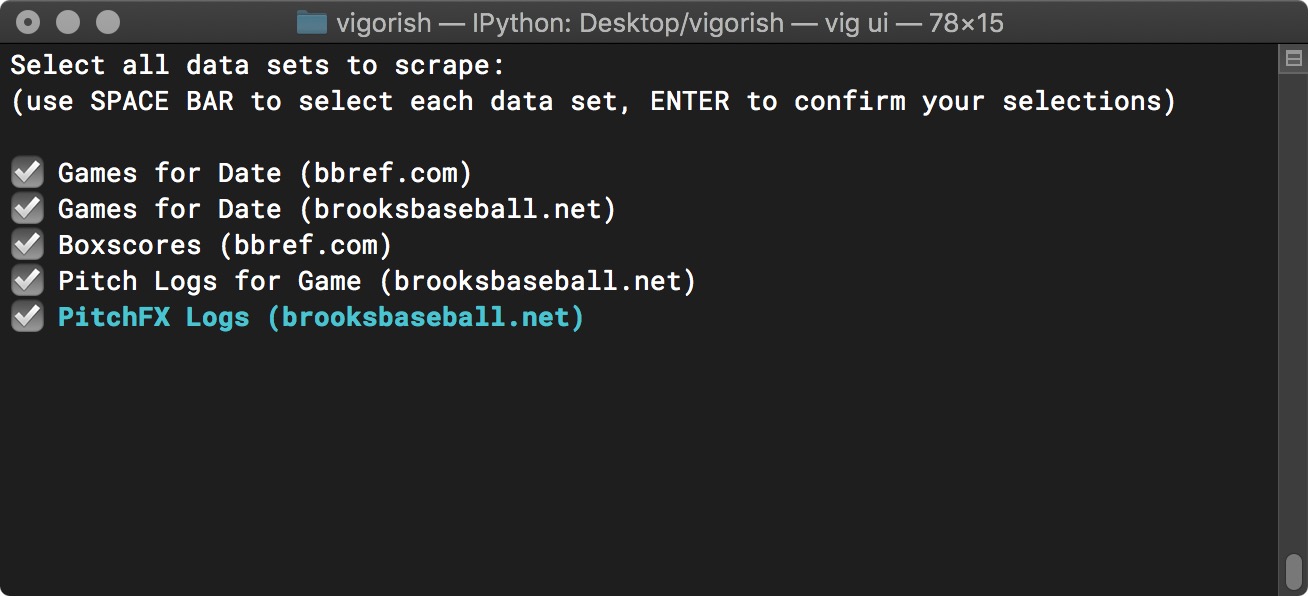
Create Job Step 1b - Select Data Sets
In the next menu, the start/end dates and job_name are also helpfully pre-populated for you. The value for Start Date is unchanged (5/2/2019), and the value for End Date has been changed to 6/9/2019. Also, the Job Name which previously was not provided has been changed to “new_job”:
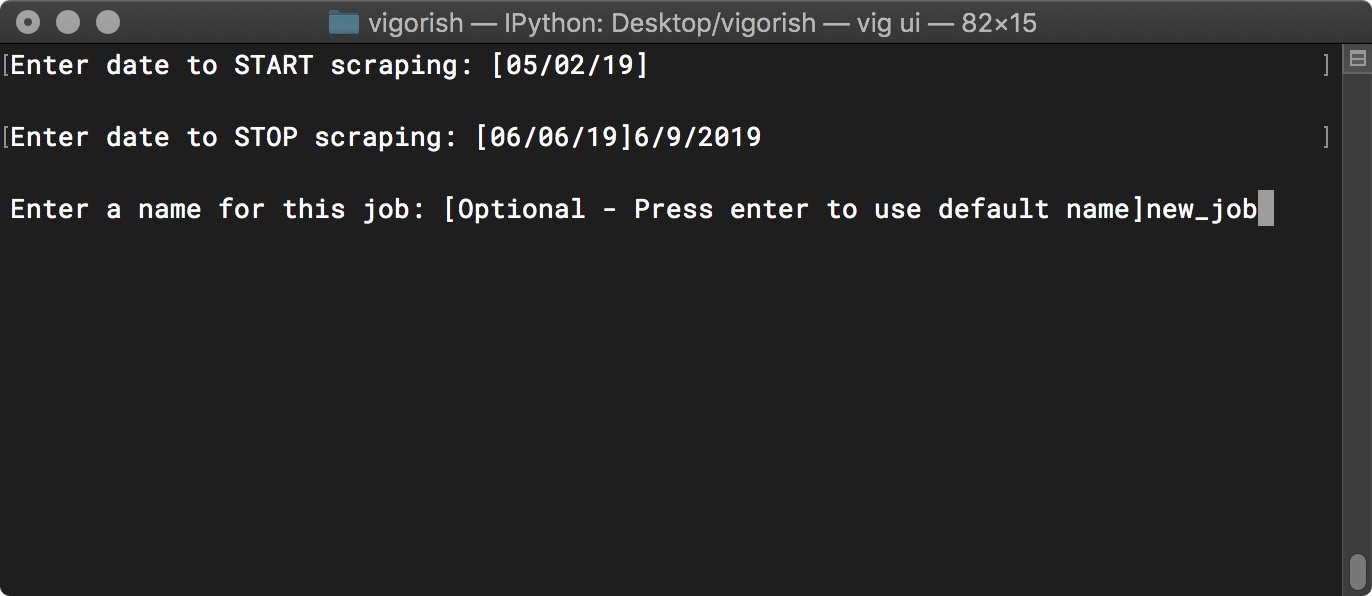
Create Job Step 2b - Edit Job Details
After updating these values, you are again asked to confirm the job details. Note that the values for Job Name, End Date and Data Sets have changed:
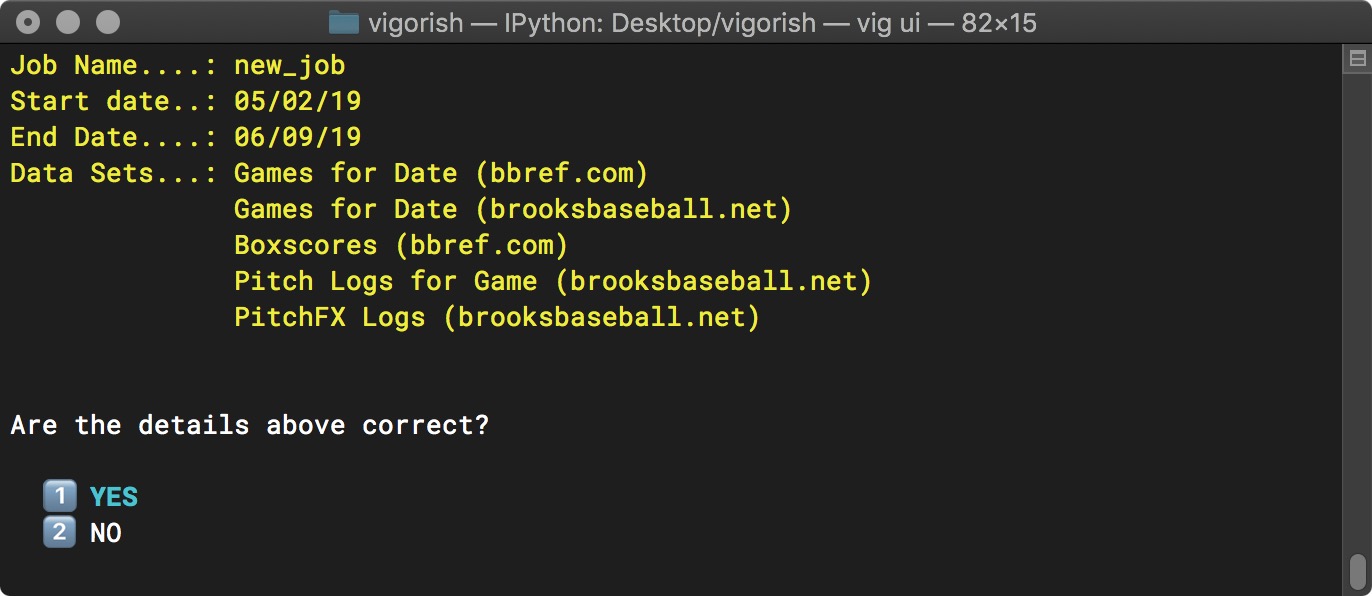
Create Job Step 3b - Confirm Job Details
After confirming the job details are correct, you are asked if you would like to begin executing this job:
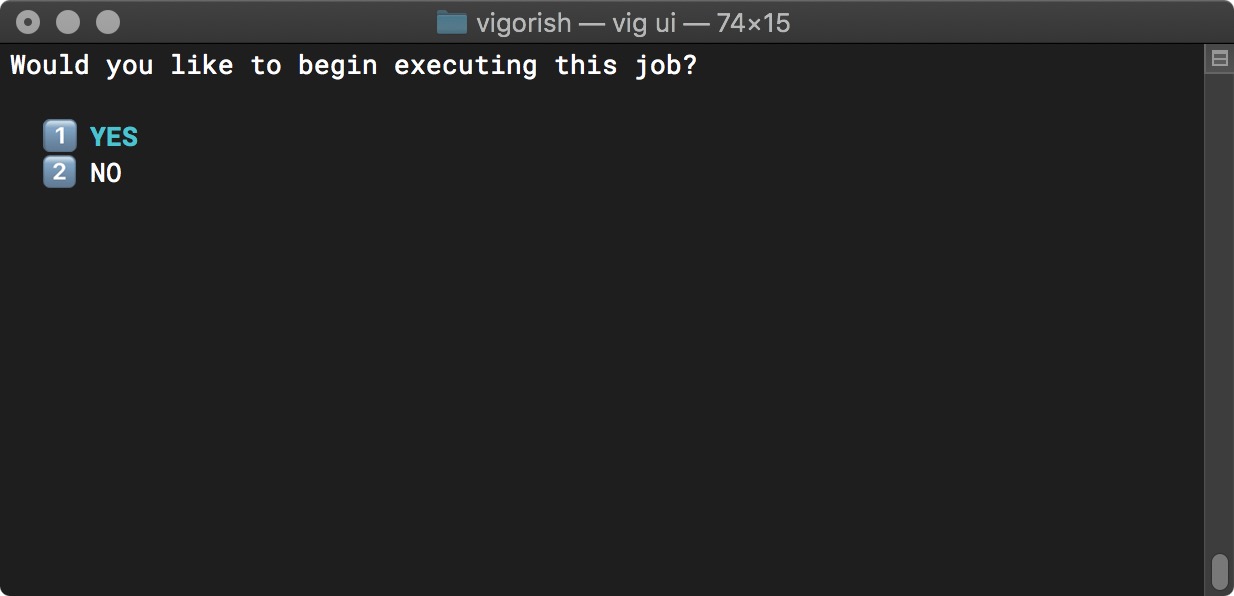
Create Job Step 4 - Prompt User - Execute Job Now?
If you select NO, you will be returned to the Main Menu. If you select YES, the job will begin executing.
Job Execution
Although you can scrape each data set individually, it is recommended that you scrape all of them together. Why? For any date, the following conditions must be met in order to scrape each data set:
| Table 1 | |
| Requirement to Scrape Each Data Set | |
| Data Set | Must Be Scraped for Same Date |
|---|---|
| Games for Date (bbref.com) | |
| Games for Date (brooksbaseball.net) | Games for Date (bbref.com) |
| Boxscores (bbref.com) | Games for Date (bbref.com) |
| Pitch Logs for Game (brooksbaseball.net) | Games for Date (brooksbaseball.net) |
| PitchFX Logs (brooksbaseball.net) | Pitch Logs for Game (brooksbaseball.net) |
These requirements dictate that data sets must be scraped in (nearly) the exact order that they are listed in Table 1. The only flexibility is that Games for Date (brooksbaseball.net) and Boxscores (bbref.com) can either be scraped second or third. As for the remaining data sets, Games for Date (bbref.com) must always be scraped first, Pitch Logs for Game (brooksbaseball.net) must always be scraped fourth and PitchFX Logs (brooksbaseball.net) must always be scraped last.
Job execution is performed in the following manner:
- For each selected data set
- For each date in the range Start Date - End Date
- Build list of all URLs for this data set on this date
- Identify URLs which can be skipped if already scraped
- Retrieve cached HTML from local folder and/or S3 bucket
- Scrape HTML for URLs that are not cached
- Save scraped HTML to local folder and/or S3 bucket
- Parse domain objects from HTML and write to JSON file
- Save parsed JSON to local folder and/or S3 bucket
- For each date in the range Start Date - End Date
You can see an example of a job where all data sets are selected in the images below. After successfully scraping the first three data sets, the fourth data set (Pitch Logs for Game) is in progress. Batch scraping is enabled, and the screenshot below is taken when the first of two URL batches is almost complete:
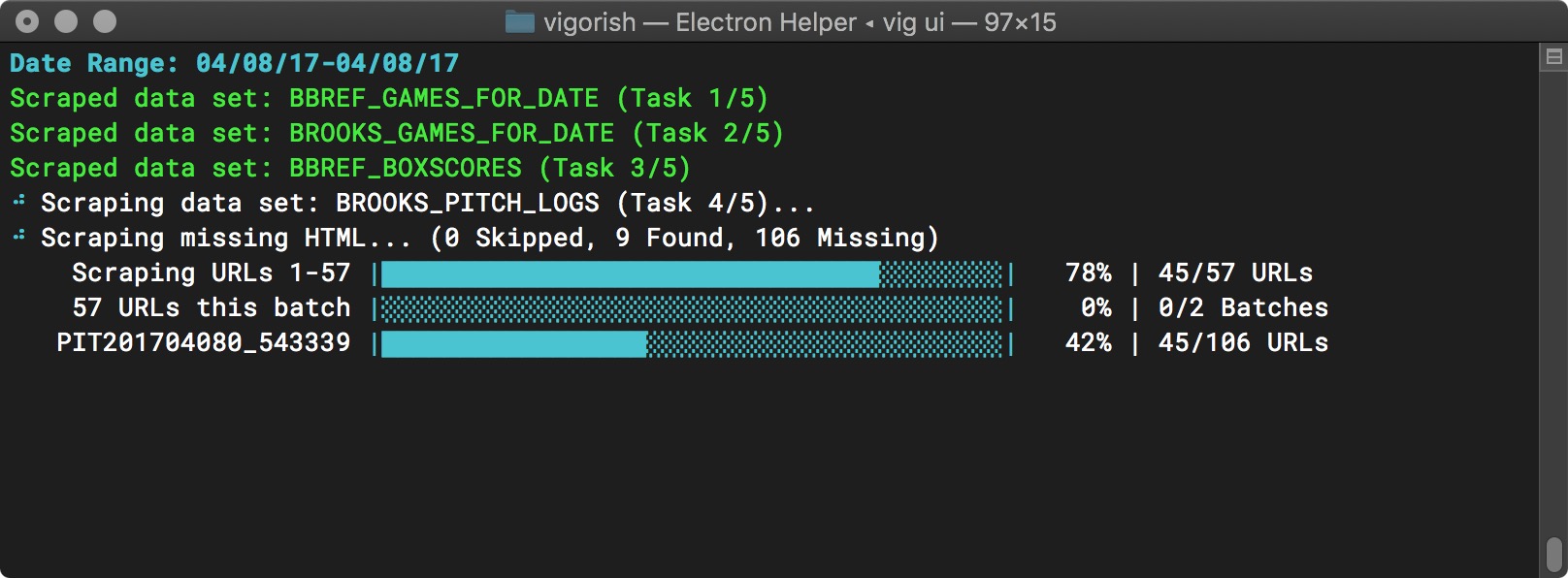
Batch Job Execution - Batch 1 Nearly Complete
After the first batch is complete, a timeout occurs. As shown below, the time remaining is displayed and the top progress bar goes from full to empty along with the time remaining:
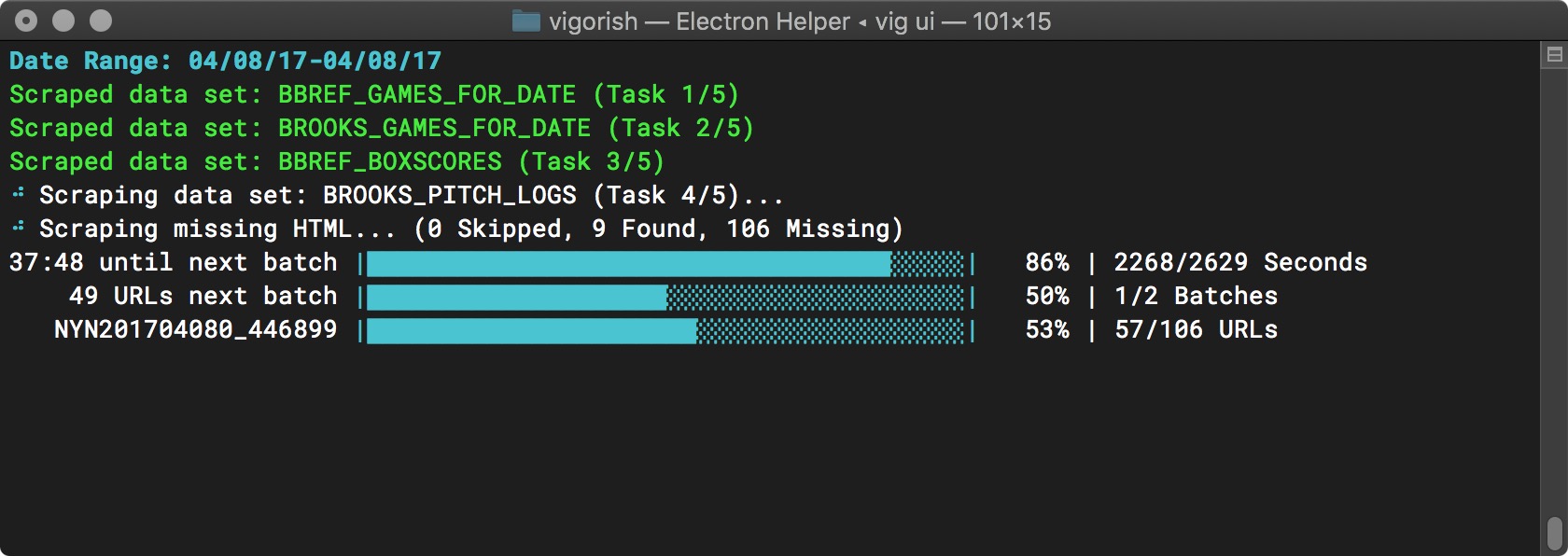
Batch Job Execution - Timeout Started
Here, the timeout is almost over. The top progress bar is nearly empty:
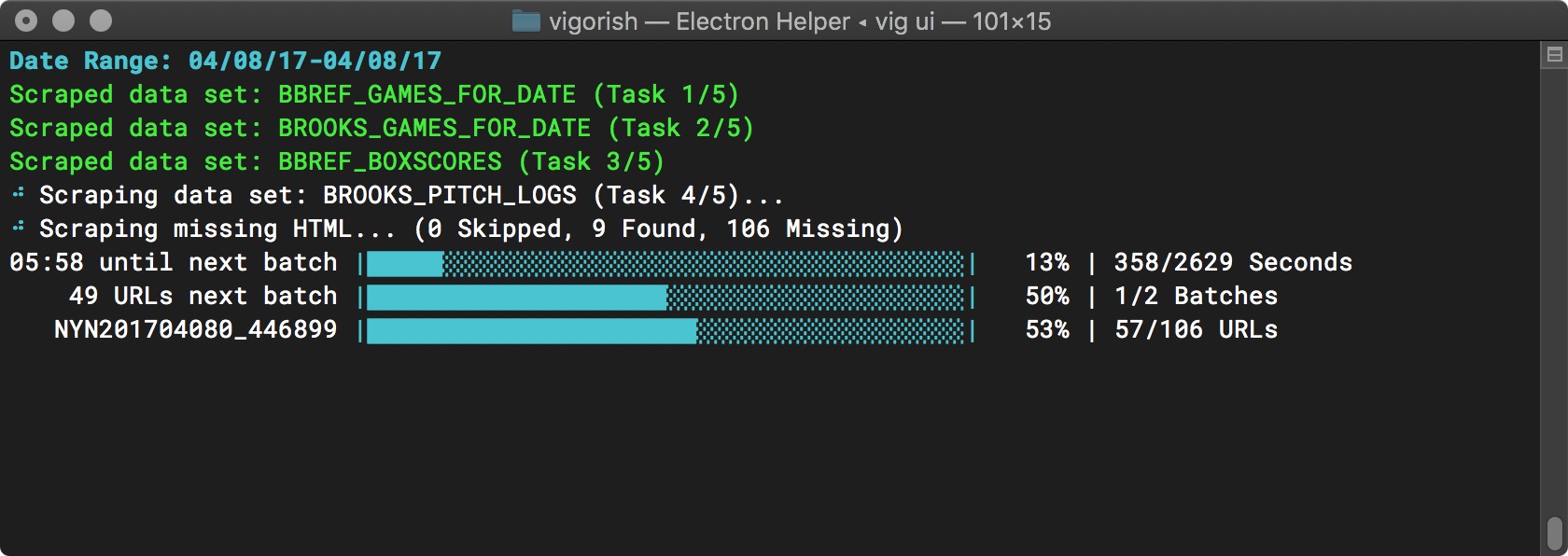
Batch Job Execution - Timeout Nearly Complete
When the timeout ends, the second batch is scraped. Notice that the number of URLs in the current batch is shown, as well as the overall total number of URLs scraped, and the number of URLs scraped in this batch:

Batch Job Execution - Batch 2 Started
Here the second (and final) batch is nearly complete:
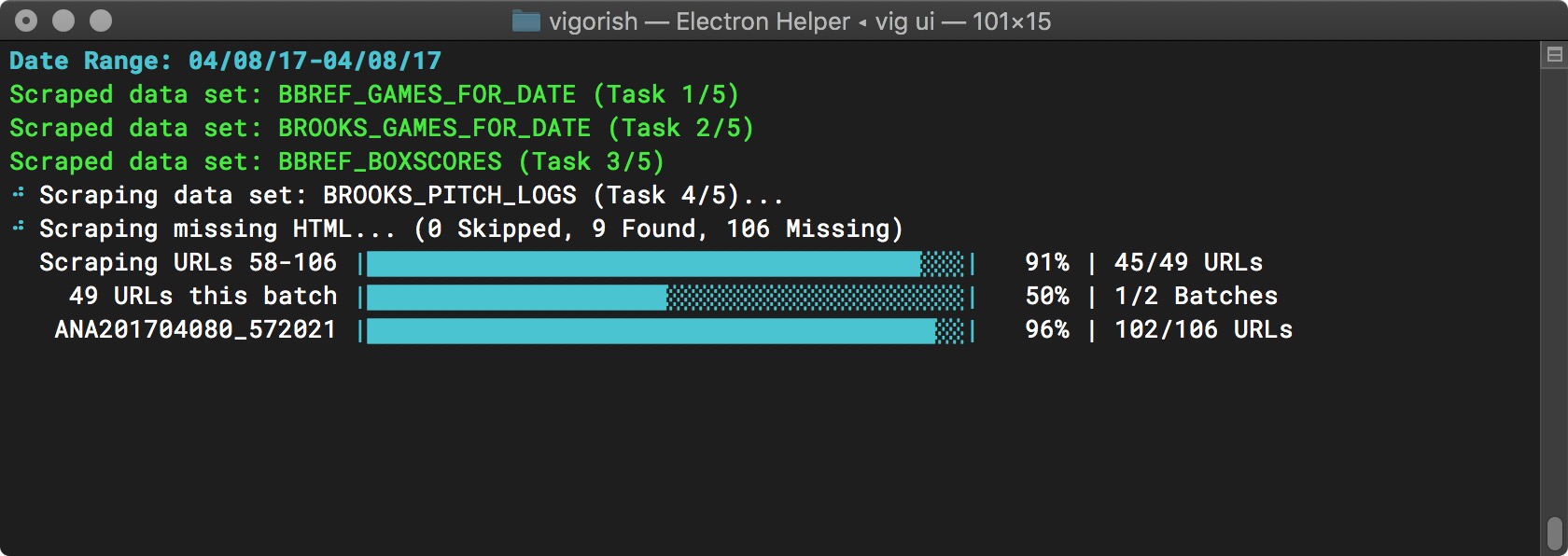
Batch Job Execution - Batch 2 Nearly Complete
When all URLs for this data set have been scraped, the next step is to save the scraped HTML to local folder and/or S3 based on your configuration settings:
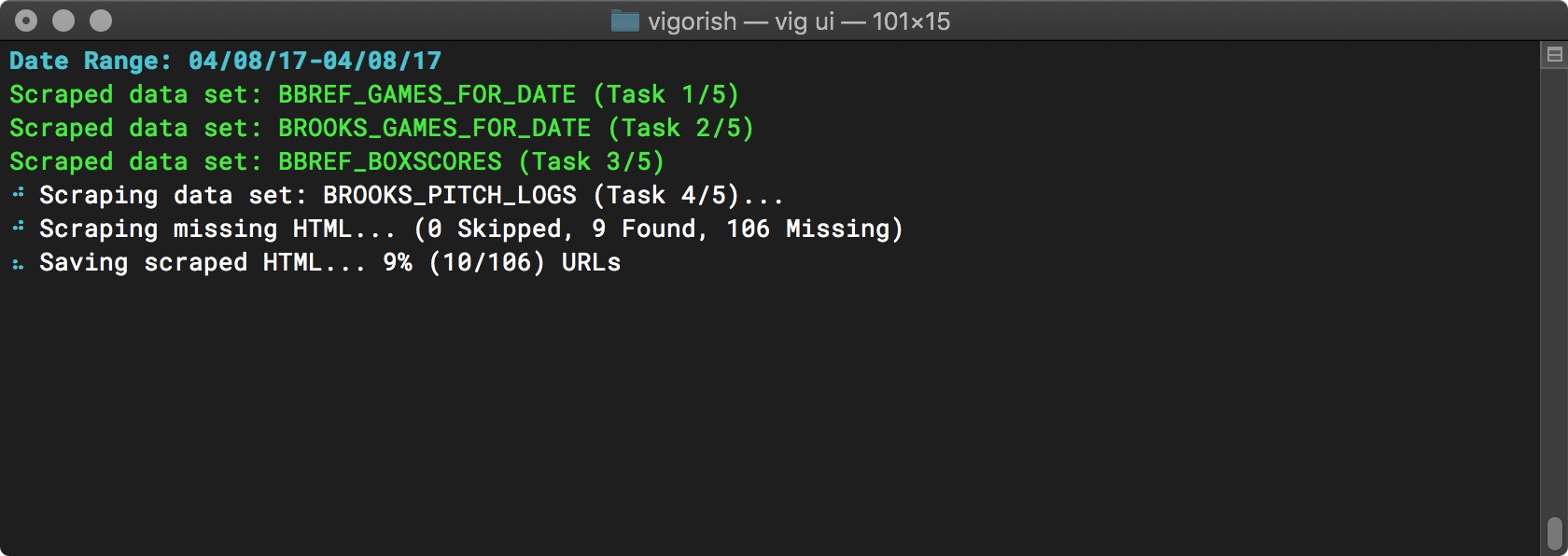
Saving HTML
Finally, the scraped HTML is parsed and the data parsed from the HTML is written to a JSON file. The JSON is saved to local folder and/or S3 based on your configuration settings:
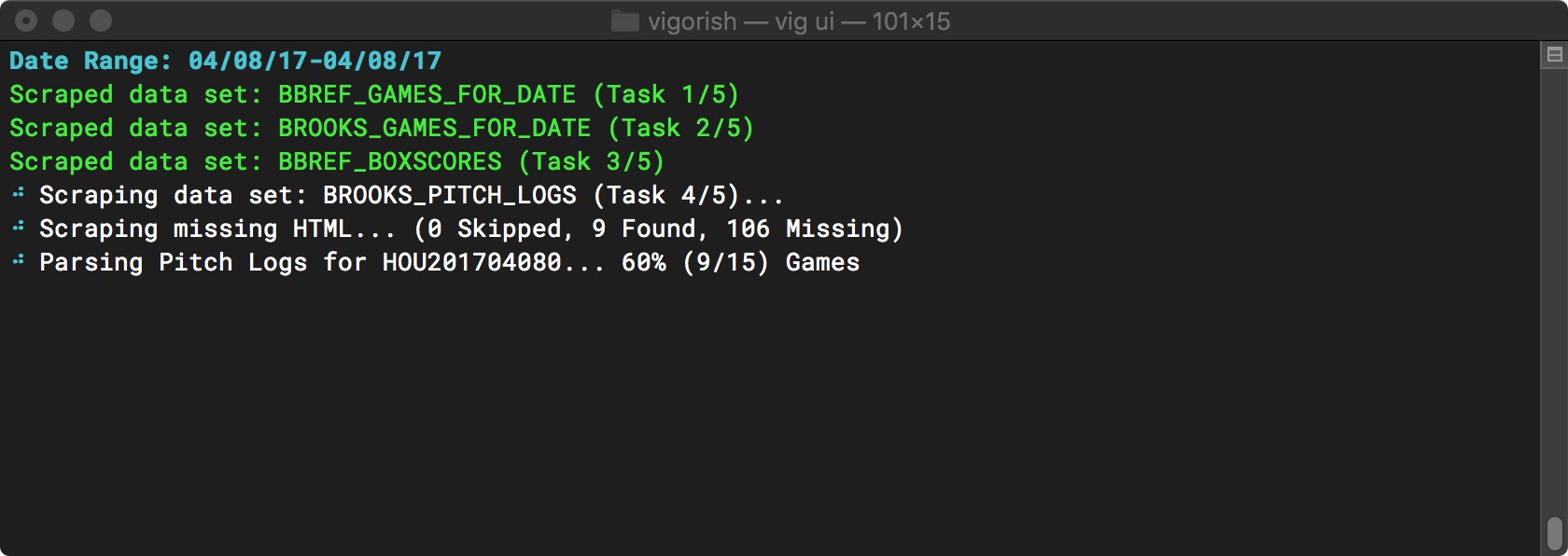
Parsing HTML
Jobs can be cancelled by pressing Ctrl+C. This will cause the message shown below to display:
Stop Job Execution
This can be very useful for long-running jobs since you will not lose any of the progress made, and you can easily resume executing the job at a later time.
View All Jobs
Since most jobs will take a considerable amount of time to finish, vigorish makes it easy to pause and resume execution. To view the status of all jobs (incomplete and complete), select View All Jobs from the Main Menu:
Main Menu (View All Jobs Selected)
The next screen divides all jobs into two categories: Incomplete and Complete. First, let’s take a look at the list of Incomplete jobs:
View All Jobs (Incomplete Jobs Selected)
The name used to identify each job is the optional Job Name value. If you did not provide a name, the ID will be used to identify the job (ID is a randomly generated 4-digit hex string):
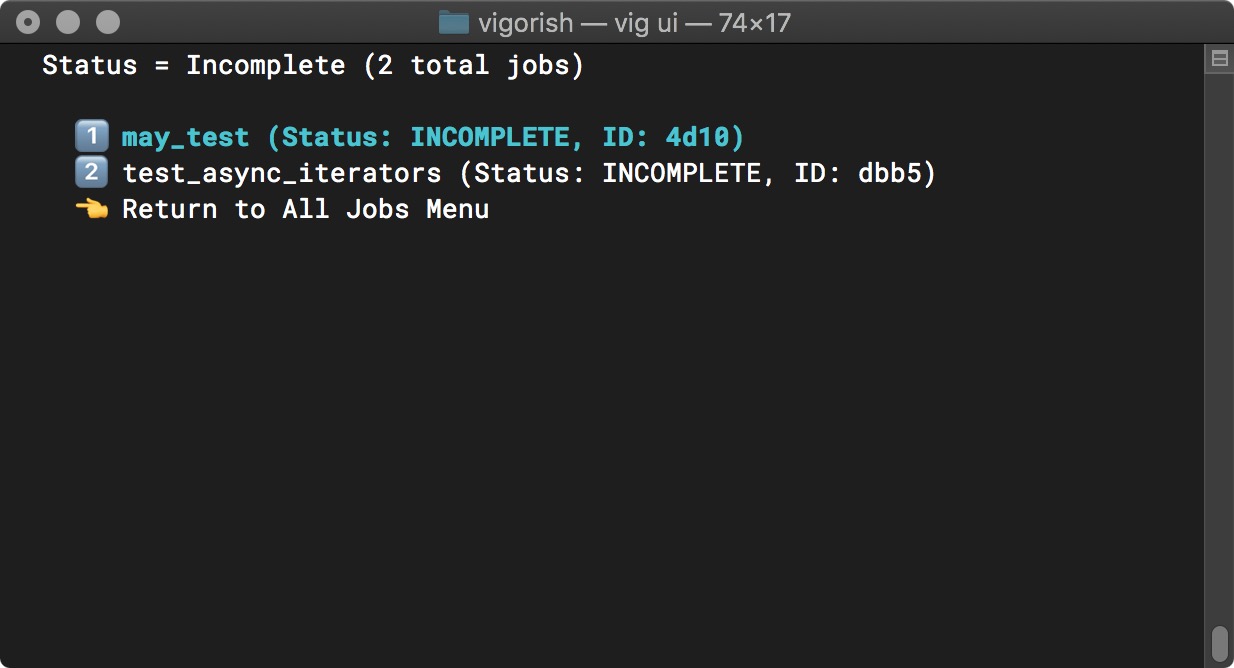
Select A Job (All Incomplete)
If you select a job from the list, you will see a summary of the job details and be prompted to either execute the job, cancel the job or do nothing and return to the previous menu. This prompt only appears for incomplete jobs.
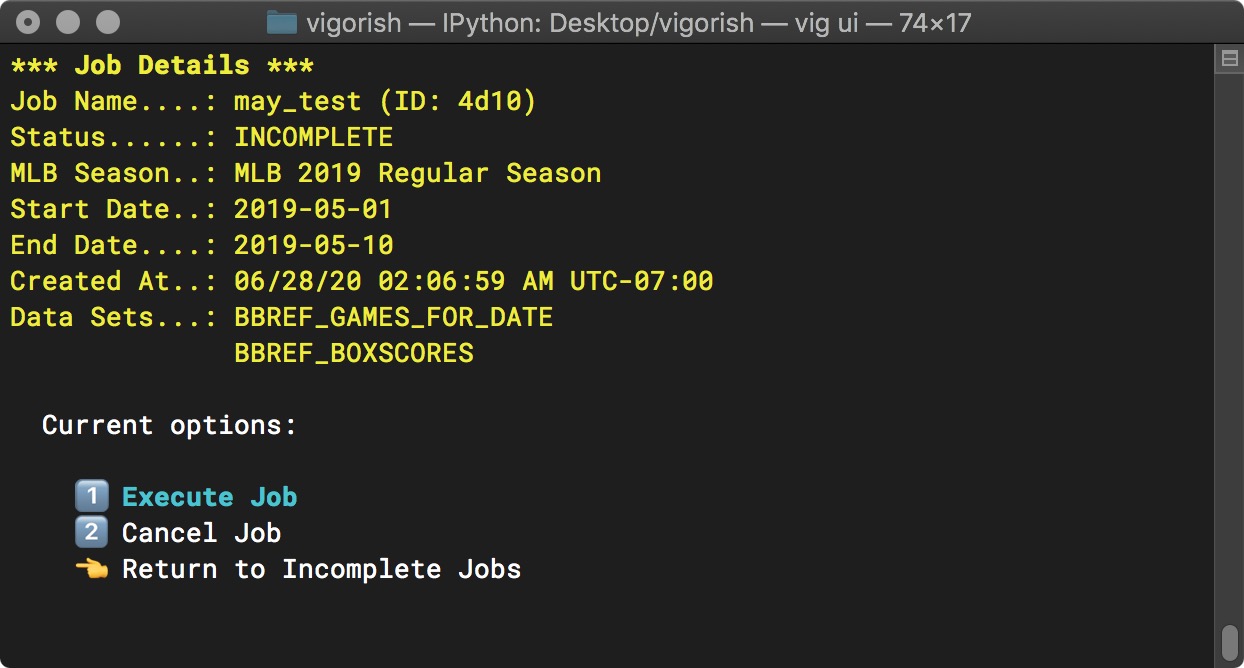
Incomplete Job Options
If we return to the initial View All Jobs menu, we can see the difference by selecting the completed jobs:
View All Jobs (Complete Jobs Selected)
The completed jobs are displayed in a list exactly as the incomplete jobs were:
Select A Job (All Completed)
However, if we select a completed job, there is no prompt shown:
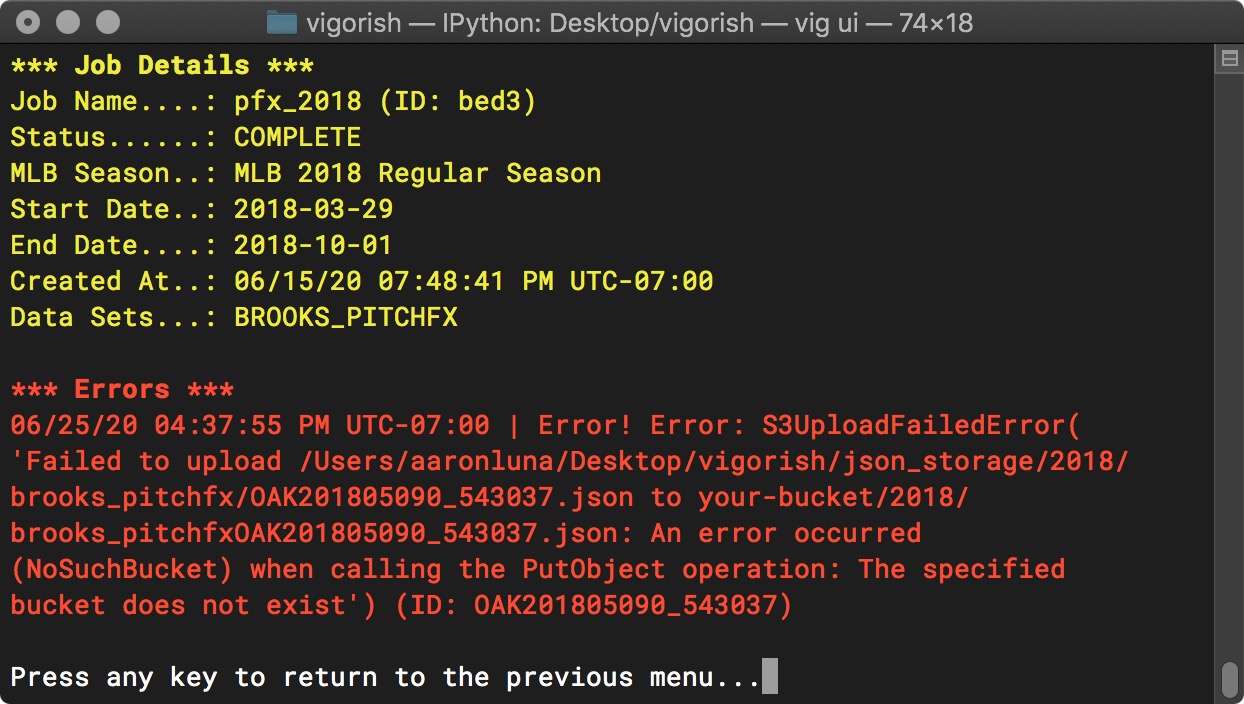
Complete Job Options
As you can see, if an error occurs while a job is running, it is logged and can be viewed in this menu.
Status Reports
My goal with vigorish was to collect all pitching data for a single season, so having the ability to track my progress towards that goal and identify any missing pieces of data is important. You can view the status of your scrape effort in many different ways using the Status Reports item in the Main Menu:
Main Menu (Status Reports Selected)
You can select from three types of reports. The first option, Season, is selected in the screenshot below:
Select Report Type
In order to report on an entire MLB Season, you must specify which season to report on:
Select MLB Season to Report
Finally, select the level of detail for the report:
Select Level of Detail
The Season Summary report is useful for understanding the overall progress you have made with all data sets:
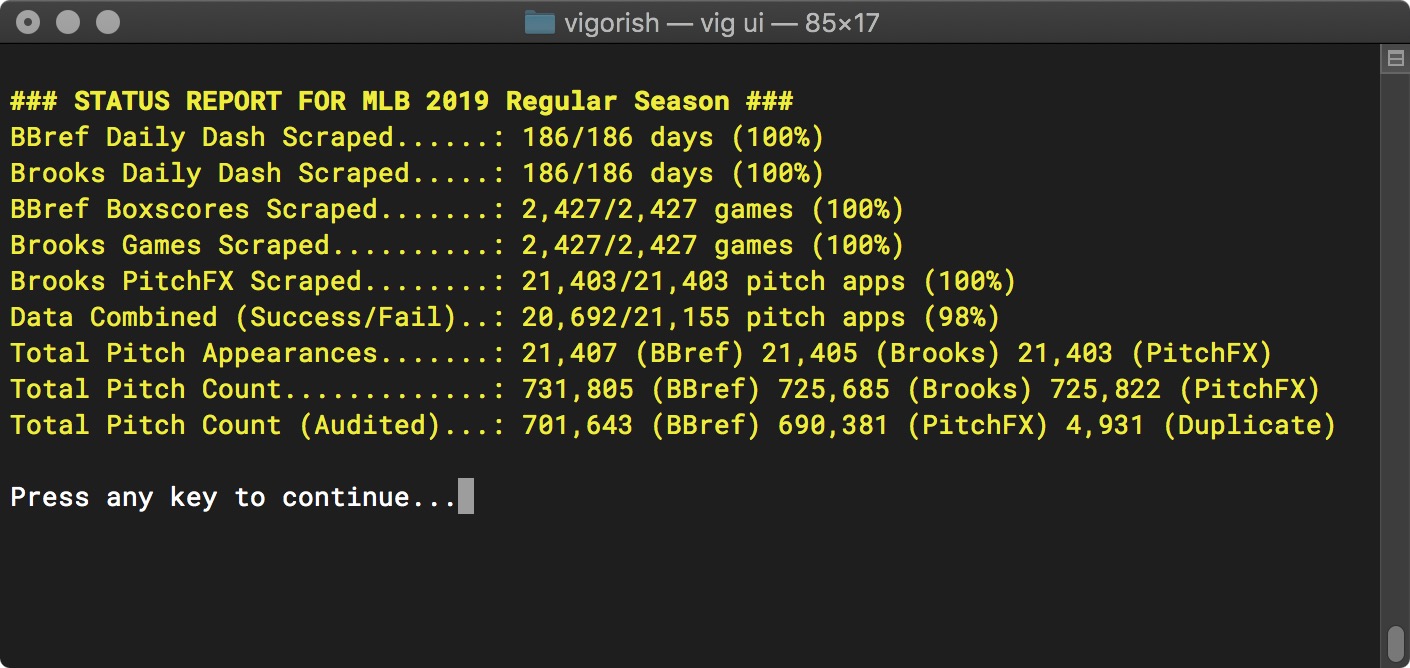
Season Status Report for 2019
The screenshot below is an example of a Single Date report:
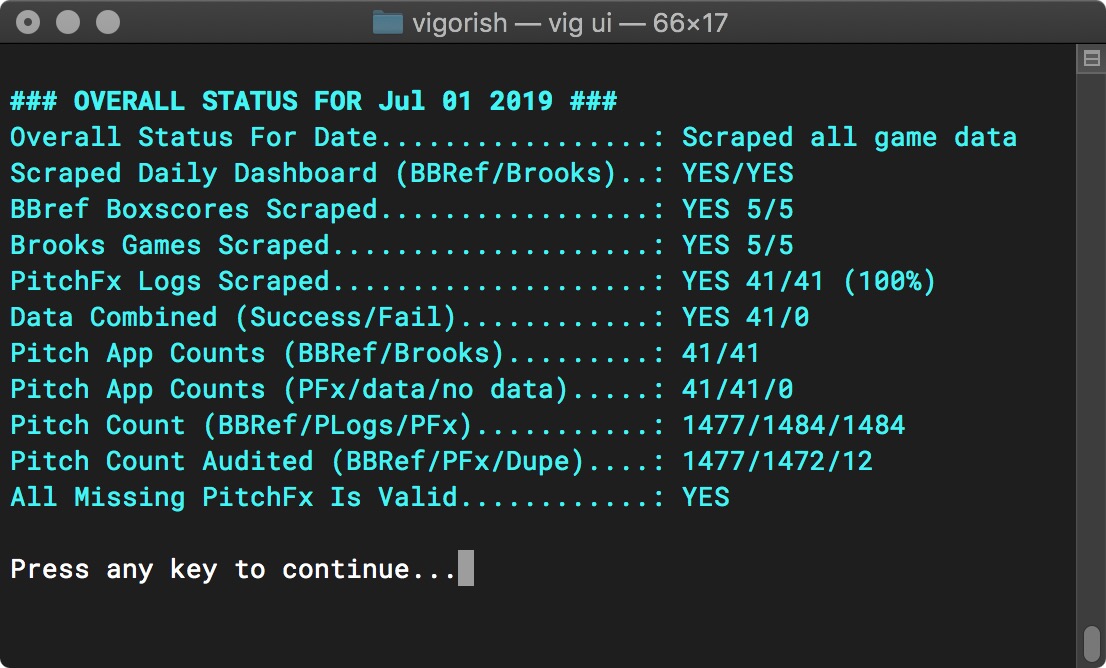
Status Report for Single Date
And this screenshot is an example of a Date Range report:
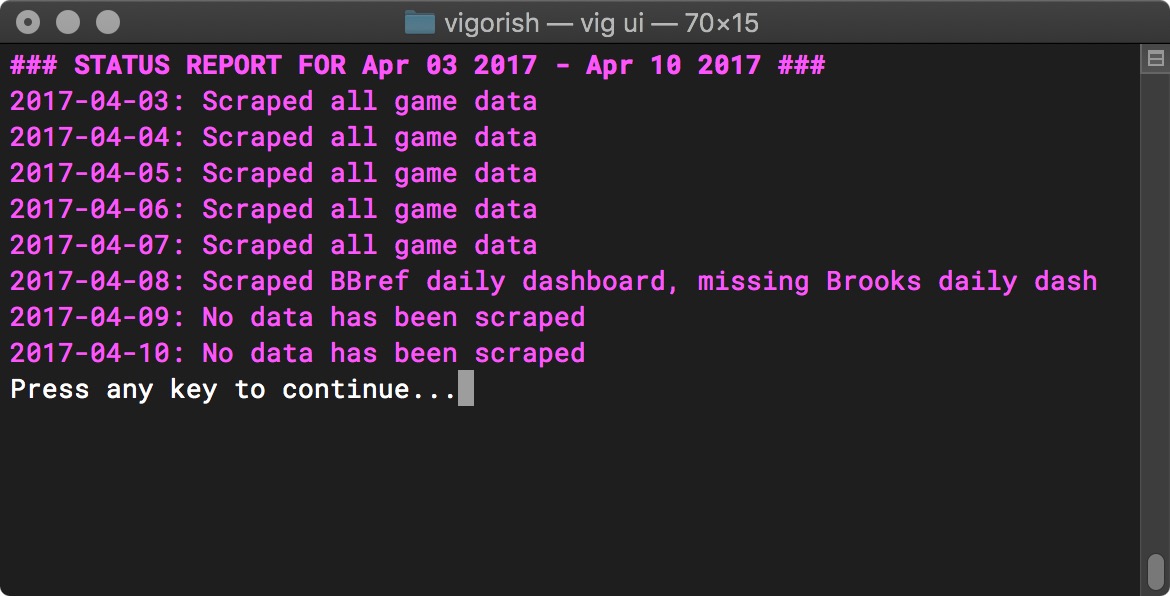
Status Report for Date Range